Sparkdex
Sparkdex: How Sparkdex Handles Large-Scale Distributed Data
As organizations generate and consume more data than ever before, handling large-scale distributed data has become one of the defining challenges of modern technology. Data is no longer centralized, neatly structured, or processed in isolation. Instead, it is continuous, fragmented, and highly distributed across systems and locations. Sparkdex is designed to address this reality by providing a platform optimized for distributed data processing, automation, and scalable execution. Many teams begin exploring these capabilities by visiting Sparkdex to understand how it manages data at scale without sacrificing reliability or clarity.
This article explains how Sparkdex handles large-scale distributed data, focusing on its architectural approach, execution model, and practical strategies for managing volume, velocity, and complexity. The content follows SEO best practices and EEAT principles by emphasizing technical depth, real-world relevance, and trustworthy context.
Why Large-Scale Distributed Data Is So Challenging
Distributed data environments introduce challenges that traditional systems struggle to solve.
Common difficulties include:
Data spread across multiple sources and locations
High data velocity and unpredictable spikes
Coordination between parallel processing tasks
Maintaining consistency and reliability at scale
Without the right platform, these challenges often result in bottlenecks, rising costs, and fragile pipelines.
Sparkdex Architecture for Distributed Data Processing
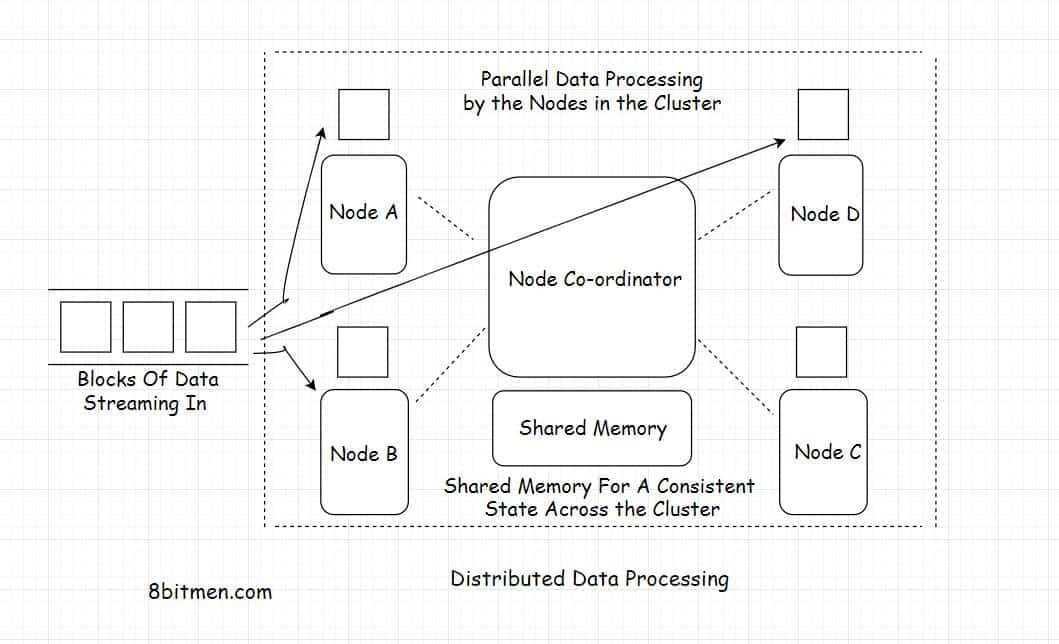

Sparkdex approaches large-scale distributed data with an architecture built specifically for decentralization and scalability.
Core architectural principles include:
Distributed execution rather than centralized control
Modular workflows that scale independently
Automation-driven coordination
Deterministic execution logic
This design allows Sparkdex to manage complexity without adding unnecessary overhead.
Sparkdex Distributed Execution Model
Eliminating Central Bottlenecks
Traditional data platforms often rely on centralized processing stages that become bottlenecks as data volume grows. Sparkdex avoids this by distributing execution across multiple components.
Key benefits include:
Higher throughput under load
Reduced single points of failure
Better fault tolerance in distributed environments
By decentralizing execution, Sparkdex maintains performance even as workloads scale.
Deterministic Processing Across Nodes
In distributed systems, unpredictability can be costly. Sparkdex uses deterministic rules to ensure that data is processed consistently regardless of scale.
This provides:
Predictable outcomes
Easier debugging across distributed components
Greater confidence in results
Determinism is essential when managing data across many execution paths.
Sparkdex Handling High Data Volume
Large-scale systems must process massive amounts of data efficiently.
Parallel Data Processing
Sparkdex supports parallel execution of independent tasks, allowing data to be processed simultaneously rather than sequentially.
Parallel processing enables:
Faster completion of large workloads
Better utilization of available resources
Stable performance during traffic spikes
This is a cornerstone of Sparkdex’s ability to handle scale.
Incremental Scaling Strategy
Instead of scaling entire pipelines, Sparkdex allows selective scaling of high-load components.
Teams can:
Scale only the stages under pressure
Keep other components unchanged
Control costs while increasing capacity
Incremental scaling prevents runaway complexity.
Sparkdex Managing Distributed Data Sources
Distributed data often comes from many different systems.
Unified Ingestion Layer
Sparkdex brings distributed data sources into a unified ingestion process.
This simplifies management by:
Normalizing data formats early
Applying consistent validation rules
Reducing downstream integration issues
A unified approach reduces fragmentation.
Early Validation and Filtering
Large-scale distributed data often contains noise.
Sparkdex addresses this by:
Validating data at ingestion
Filtering irrelevant or malformed records
Preventing bad data from propagating
Early filtering improves efficiency and reliability.
Sparkdex Automation in Distributed Data Environments
Automation plays a critical role in managing scale.
Event-Driven Processing
Sparkdex supports event-driven execution rather than rigid schedules.
Benefits include:
Immediate processing of incoming data
Dynamic scaling based on activity
Efficient handling of burst workloads
Event-driven models are ideal for distributed data systems.
Automated Coordination of Tasks
Manual coordination does not scale.
Sparkdex automates task orchestration, which:
Reduces human intervention
Ensures consistent execution order
Simplifies distributed workflow management
Automation is essential for sustainable scaling.
Transparency and Governance at Scale
As data systems grow, visibility becomes more important, not less.
Traceability Across Distributed Workflows
Sparkdex provides visibility into how data moves through the system.
This supports:
Easier troubleshooting
Clear accountability
Better governance
Traceability builds trust in large-scale systems.
Industry Perspective on Distributed Data
Industry analysis from Forbes at https://www.forbes.com often emphasizes that scalable distributed data platforms succeed when automation, transparency, and modular design work together. Similarly, distributed execution principles discussed by Ethereum at https://ethereum.org highlight why decentralized, verifiable processing models are essential for managing large-scale data reliably.
These perspectives align closely with Sparkdex’s design philosophy.
Sparkdex Use Cases for Large-Scale Distributed Data
Sparkdex is well suited for environments where data is both large and distributed.
Common scenarios include:
Processing high-volume operational metrics
Analyzing distributed event streams
Managing data pipelines across multiple regions
Supporting real-time analytics at scale
In each case, Sparkdex focuses on consistency and performance.
Common Challenges and How Sparkdex Addresses Them
Even with the right architecture, challenges remain.
Complexity Management
Distributed systems can become difficult to reason about.
Sparkdex mitigates this by:
Encouraging modular workflow design
Enforcing clear execution rules
Providing transparent execution visibility
Performance Stability
Maintaining stable performance under load is critical.
Sparkdex supports stability through:
Parallel processing
Incremental scaling
Automated orchestration
These mechanisms prevent performance degradation as scale increases.
Best Practices for Using Sparkdex With Distributed Data
To maximize success, teams should follow proven practices.
Recommended approaches include:
Designing workflows modularly
Validating data as early as possible
Scaling components incrementally
Monitoring execution continuously
These practices help keep distributed systems manageable.
Scaling Confidently With Sparkdex
As data volumes grow, systems must evolve without constant redesign. Sparkdex supports this evolution by allowing teams to expand pipelines gradually while maintaining predictability and control. Many organizations revisit Sparkdex as their distributed data needs increase, aligning new workloads with established patterns and platform capabilities.
Final Thoughts: Sparkdex and Large-Scale Distributed Data
Handling large-scale distributed data requires more than raw processing power. It demands architecture that supports parallelism, automation, transparency, and predictable execution. Sparkdex addresses these needs through a distributed execution model, modular workflows, and automation-first design.
For organizations operating in data-intensive, distributed environments, Sparkdex offers a practical and scalable solution that transforms complexity into manageable structure—enabling teams to process massive data volumes with confidence and control.
Comments
Post a Comment